
Hundreds of cyclists are involved in accidents on the roads, which results in people hesitating to commute by bicycle because it is perceived as dangerous. Some of the main risk factors are associated with pavement quality, which is a crucial factor to consider when evaluating cycling safety. Pavement quality refers to the quality of the road when there is no cycle lane or to the cycle lane itself when it exists. The presence of water drainers, potholes, or trail portions contributes to the decrease in the pavement quality of cycle lanes.
Decreased quality of a cycle lane can either lead to an accident occurring on the cycle lane itself - for example, a cyclist falling due to a pothole - but also lead to the cyclist not using the cycle lane out of safety concerns, which forces the usage of the road and increases the risk of accidents with motorized vehicles.
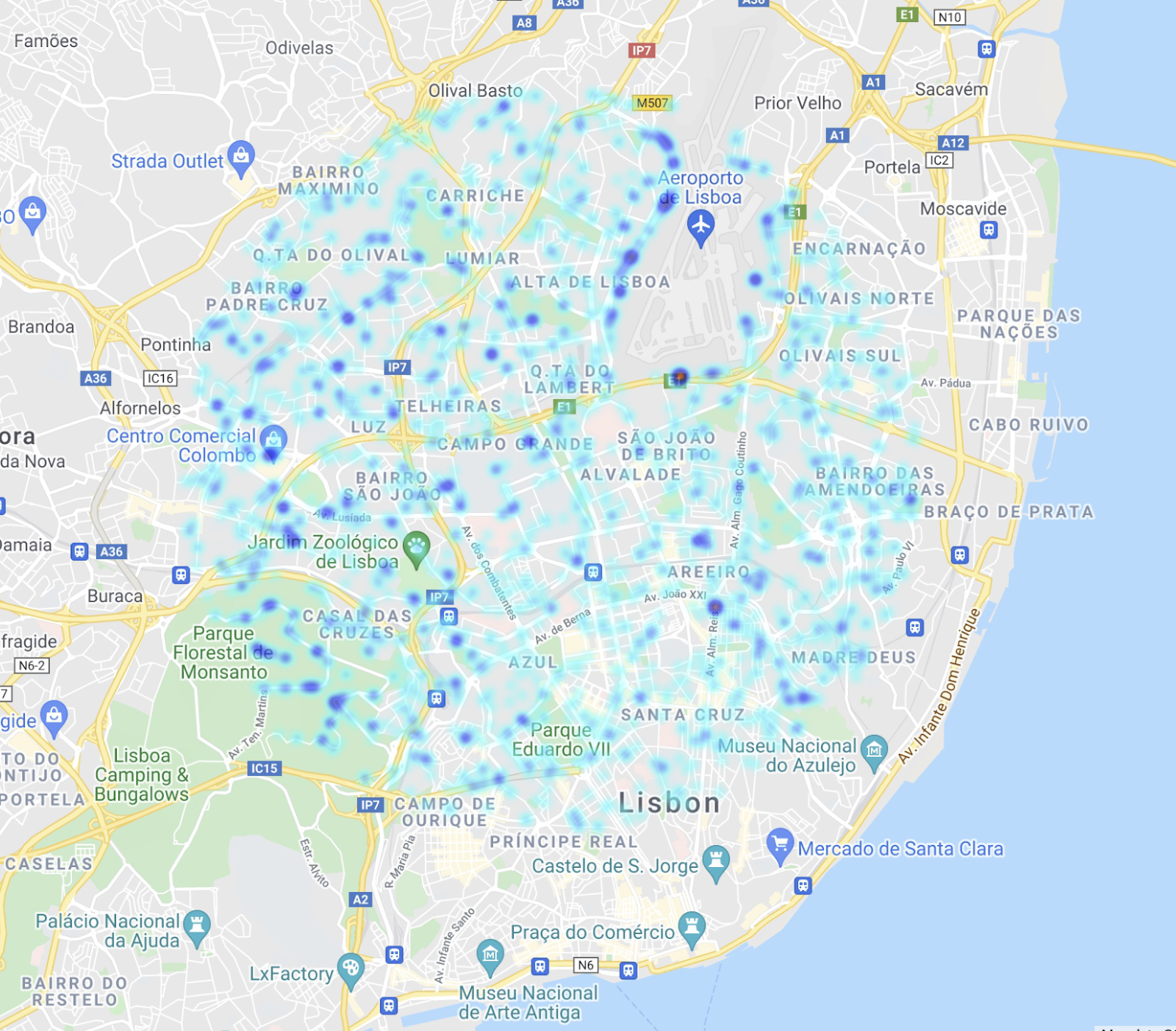
Create a high-resolution map of Lisbon with an embedded layer of pavement quality.
GOAL 11: Sustainable Cities and Communities
The following datasets were provided to the participants:
Mostly due to the fact that the provided data did not contain annotation, teams had the option of either manually annotating data or gathering pre-annotated open datasets. Most teams resorted to the second option, which led to teams using either the RoadDamageDetector dataset or the Kaggle Pothole dataset.
The first one was produced regarding a data competition in 2020 and contains data from Japan, India, and the Czech Republic. This data consists of pre-annotated images with classes that represent several types of pavement defects, such as cracks, crosswalks and line blurs, and potholes. The second dataset was produced during a Kaggle competition and contains 665 images of roads with potholes labeled.
Another team gathered open data about the cycle network of Lisbon as a way to relate it with the provided dataset. This team suggested adding more data regarding cycling accidents, time-series data with the number of bicycles crossing a certain area, and a pre-segmentation of the road section for model classification.
Since this problem was a Computer Vision challenge and the provided dataset was not annotated, all teams had to define an alternative solution to train a prediction model. Additionally, teams defined “pavement quality” differently, and for that reason, they focused on different scopes of the issue.
One team framed the problem as one of pothole detection. They started by segmenting the images on the dataset to identify only road segments and exclude the rest. For that, they used a pre-trained Keras model that was trained on the Cityscapes dataset, which is available as open data. Afterward, they manually annotated part of the dataset using HyperLabel to train a YOLOv5 algorithm. They trained this model in 3000 epochs, following the recommendations from a Roboflow notebook. After detection, the team then computed the area of the road segment and the area of the pothole for each image, and by calculating the ratio between the two they used it as a measurement of the risk rate of each image.
Several other teams used the same algorithm but framed the problem differently. For example, one team used an external dataset that was already annotated, the RoadDamageDetector, which not only saved the effort of manually annotating data but also enabled them to identify which types of pavement defects to focus on since it comes with preloaded classes. This team also used the Pareto Theory to identify which pavement defects to focus on first since the distribution of the occurrences of these defects is not equal. On the other hand, there was a team that, while using both YOLOv5 and a pre-annotated dataset for training, resorted to a different dataset - the Kaggle Pothole dataset. As the name indicates, this dataset focused exclusively on potholes, which limited the scope of the solution.
On a different note; there was a team that approached the problem in a very different way from a technical point of view. This team also did manual annotation of images but established their own annotation policy with the intent of detecting what they perceived were risk factors in pavement quality. They looked at three characteristics, each one with its own classes - street width (single car, double car), pavement type (tar, cobblestone, unpaved), and pavement quality (low, high) - and assigned a risk factor to each class in order to differentiate higher and lower risk. The team then built a car detector using YOLOv5 and assumed that the presence of detected cars in a certain region could be indicative of the risk level for cycling. They built three different predictive models - one for each category - and then averaged out the predictions along with the assigned risk factor.
One team did a data analysis on their predictions and found that the vast majority of images had no defects, but when they exist, the most common are potholes. However, the team does not suggest starting by fixing all the potholes. Instead, they propose a more sophisticated strategy for tackling the pavement quality issue, following their Pareto distribution analysis: starting by fixing the 20% of roads that have more than 50% of defects.
Another team also analyzed their predictions and found some key insights on their data regarding streets in Lisbon - for example, the fact that one single avenue had 29 potholes and seemed in urgent need of repair work, especially considering its proximity to the airport. They also analyzed in this specific avenue how much time would be saved upon fixing the potholes.
Lastly, building on their proposed solution, one team made suggestions for both software developers and policymakers. For the second stakeholder, they concluded that although their algorithm outputs the risk level on a map, several high-risk zones are not appropriate to have bike lanes at all. Hence, this tool could work as a decision support system with a visual interface to help decision-makers.
In the end, all teams managed to produce a map of Lisbon indicating the pavement quality in the locations where the dataset images were taken. An example can be seen in Figure 1. Most teams agreed that a similar model could be applied to any city, which makes it very scalable. Teams also suggested that a tool like this would be useful for city planners to know where to focus in terms of repairs so that cyclists would feel safer.
Another team produced one visualization map per defect and a data-driven strategy for pavement maintenance strategy based on Uber’s H3 approach.

