
Traffic flow in cities is one of the most critical problems to address, as the increasingly higher number of cars circulating in city streets poses a daily problem for city management authorities. In some countries and cities, especially the most populated ones, traffic congestion is such an endemic issue that policymakers and researchers have been trying to solve it for decades and it is still not completely solved.
Consequently, city navigability becomes severely compromised as drivers have to wait more and more hours in traffic jams. Traffic congestion poses another problem to pedestrians (and to everyone in general) - a negative impact on health. It increases vehicle emissions and degrades ambient air quality, and recent studies have shown excess morbidity and mortality for drivers, commuters, and individuals living near major roadways.
Several cities have been putting forward efforts towards quantifying their traffic levels accurately. The city of Porto, for example, has been counting cars at several locations with inductive loop sensors since 2015. With this historical data, it is possible to predict the traffic flow and especially during intense traffic periods. By predicting traffic flow in the city and understanding the factors that influence traffic, it’s possible to take action to reduce it.
Create a predictive model for traffic flow in the city of Porto for different periods of the day from sensor data and explain which factors impact the traffic flow.
GOAL 11: Sustainable Cities and Communities
The following datasets were provided to the participants:
In addition to the provided datasets, the City of Porto also provided data regarding air quality, noise levels, and weather in its open data portal. The vast majority of teams used several of these additional data sources and merged at least one of them with the traffic intensity dataset.
One team pointed out a major limitation of the provided dataset: the considerably large number of missing values in the measurements, especially for the year 2018.
One team suggested that the small number of air quality sensors compared to the traffic sensors made them quite difficult to use due to the fact that their locations were not the same. They also suggested gathering data related to the position of traffic lights to understand the relation between their functioning and the traffic flow in that position, as well as data regarding the speed of cars that pass on the sensor.
Due to a significant problem of missing values, one team focused exclusively on data from 2019 and added an interpolation step to impute those missing values. That same team also looked for outlier measurements and found very few for that year, so they replaced the outliers with the average measurement. Both of these adjustments led to a much cleaner dataset. On the other hand, there was another team that focused extensively on outlier removal and data augmentation, which culminated in a quite large dataset for the years 2018 to 2020.
The first team also looked into autocorrelation and partial-autocorrelation to detect if there was any seasonality in the data, which they found, at seven days. The team tried two modeling approaches - a Random Forest Regressor and SARIMAX - and trained models on a per-sensor level, after which they filtered sensors based on the R2 score that was obtained. From 117 sensors, with a minimum R2-score of 0.4, they obtained 71 sensors to work with - the best-performing sensor had an R2-score of 0.72.
Another team computed several new features for model training, such as distance to the centroid of all sensor locations and many lagged features for the seven days before. They modeled the problem using a Gradient Boosting algorithm, which performed better than a model that always assumes the traffic intensity will be the same as the day before. This team also analyzed the explainability of their algorithm using Shapely Additive Explanations (SHAP), which pointed to the model focusing mostly on lagged features, month features (correlated with seasonality), and some weather features. Another team tried a very similar approach, using a Gradient Boosting algorithm, and obtained a mean error of 0.24, which was much better than the model trained as a baseline.
There was another team that approached the problem as a clustering challenge. They used PCA coupled with K-Means and produced several possibilities using three or four clusters in an effort to understand if different streets could be clustered together in categories. After that, they also did more traditional forecasting methods, even using COVID-19 data and the points of interest.
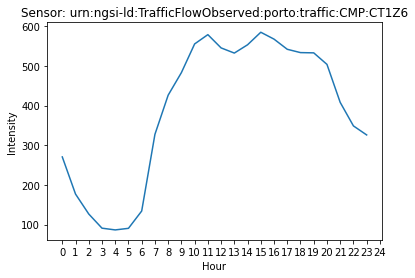
An example of the common behavior of a traffic intensity sensor can be seen in Figure 1. From 5 am onwards, cars start circulating in that position, and from 6 am to 8 am, there is a sharp rise since that is when people typically leave their homes to go to work. It peaks at around 10 am and remains fairly stable, except for lunchtime, where it fluctuates slightly. At 7 pm, it starts to decrease as people progressively return home.
By merging the several sensor data available, one team found that high traffic flow leads to higher air pollution and noise, which matches not only expectations but also the literature. They also found that, in general, most traffic flow happens during the weekdays, especially during the peak times when people commute to work and home - 6 am to 8 am and then again from 6 pm to 8 pm. During the weekend, traffic intensity is lower in general. Using the model they trained as a source of information, which made predictions for the next 72 hours, this team proposed a solution that revolved around the concept of ‘’Low Emission Zones’’ - areas of the city where speed limits and car usage is limited. These areas would function with a “color-code system”, where there would be three different levels depending on if the traffic flow was low, medium, or high.
Another team analyzed the importance of each factor contributing to traffic congestion and categorized them into three main groups: weather, time, and points of interest. Interestingly, this team found that the weather has a weight of 18% - this refers to, for example, the impact of rain on traffic congestion, which is a frequent culprit. They also found that time (day, week, month) only accounts for 14%, despite the fluctuation that occurs per time of day and weekday. And lastly, according to this team, the main contributing factor to traffic congestion is points of interest - people tend to move to and from places with more infrastructure that attracts them, such as restaurants, shopping malls, or parks.
One team proposed implementing their solution as a smart traffic-light system. By using a forecasting model to understand which zones had higher traffic intensity, a technician could manually tune the behavior of traffic lights in those zones or even have that done automatically. This would lead to a decongestion of traffic in these regions and a greater flow of cars, increasing their speed and contributing to the reduction of CO2 emissions.
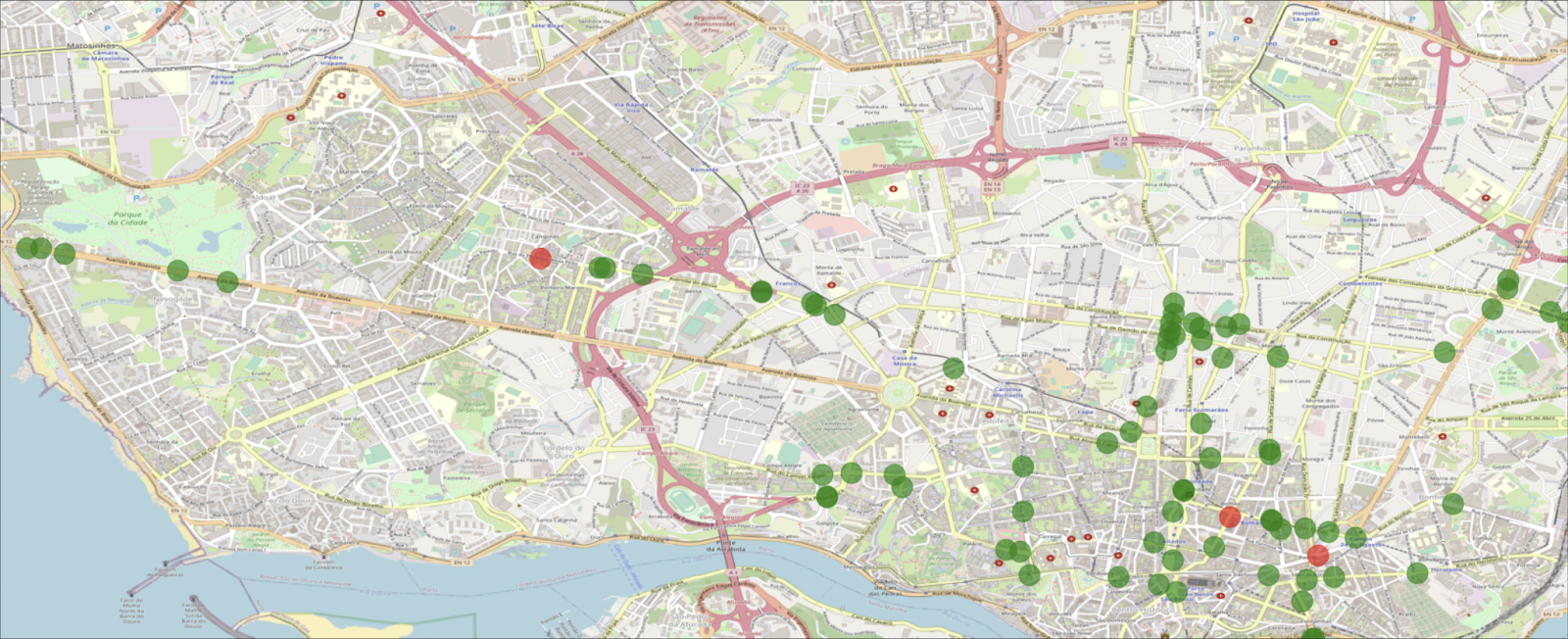
Another team proposed a traffic monitoring system similar to what’s presented in Figure 2. This system would use two colors (red and green), and using the forecasting model would output for each traffic sensor the intensity level compared to the previous day. This way, when the model predicted lower traffic than usual, that sensor would be green, and if the opposite occurred, that sensor would be red. In this case, traffic is mostly at the usual level, with the exception of a few places where traffic is expected to be more than usual.
There was one team whose work was published as a scientific paper on ‘’SoGood2021 - 6th Workshop on Data Science for Social Good’’, held in conjunction with ECML PKDD 2021, one of the major conferences in Machine Learning and Knowledge Discovery worldwide. The title of the paper is “Applying Machine Learning for Traffic Forecasting in Porto, Portugal” and it can be seen here.

