
The recent and future increase in the population that lives and works in cities will significantly pressure the infrastructure of cities, namely roads. This will increase the probability of traffic accidents, which carries significant challenges in city mobility, transportation systems, and, more importantly, human safety.
In this sense, it is of utmost importance to understand traffic accidents' infrastructural and environmental characteristics and predict them. This enables, for example, city emergency services to optimize responses to an emergency call and city managers to plan road traffic, considering the risk of traffic accidents.
Create an explainable predictive model of traffic accidents at street level by the moment of the day.
GOAL 11: Sustainable Cities and Communities
The following datasets were provided to the participants:
Most teams used only the provided dataset. One team also used weather data as input to the model. Teams argued that a more precise model could be built by providing more detailed information (e.g., the hour of each accident and the severity of the accident), information on the quality of the roads, locations of road signs, traffic data and user behavior (e.g., the demographic of the parties involved in the crash), and data on other means of transportation (e.g., cycling and pedestrians).
In this challenge, various methodologies were used for prediction. Some teams that used supervised learning approached this as a regression task (predicting the number of car accidents on the segment, with a risk factor) or as a classification task (if an accident happened, the categorical target of the number of accidents, location of the accident). A large array of models was tested by different teams as well.
One team compared five models: Random Forest with default hyperparameters and tuning, Logistic Regression, and Gradient Boosting with default hyperparameters and tuning. This team picked Logistic Regression for further prediction analysis as it had higher precision and lower recall. Another team used Random Forest and LASSO, while others used CatBoost and a Neural Network.
One team decided to take an unsupervised approach by clustering areas of accident concentration with DBSCAN. There was also a team that took a time-series approach to predict the number of accidents by day, although they did not develop a street-level model.
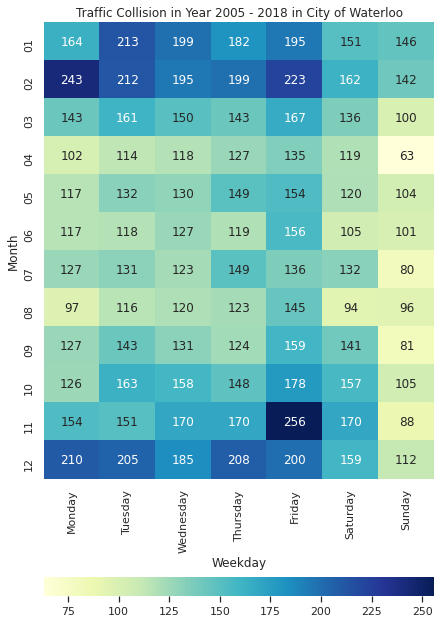
One team extensively analyzed when most accidents occur and discovered that the number is generally higher during winter and on Fridays (see Figure 1). Most of the accidents happened at or near a private driveway or non-intersection. It was also possible to observe a higher concentration of accidents in other areas.
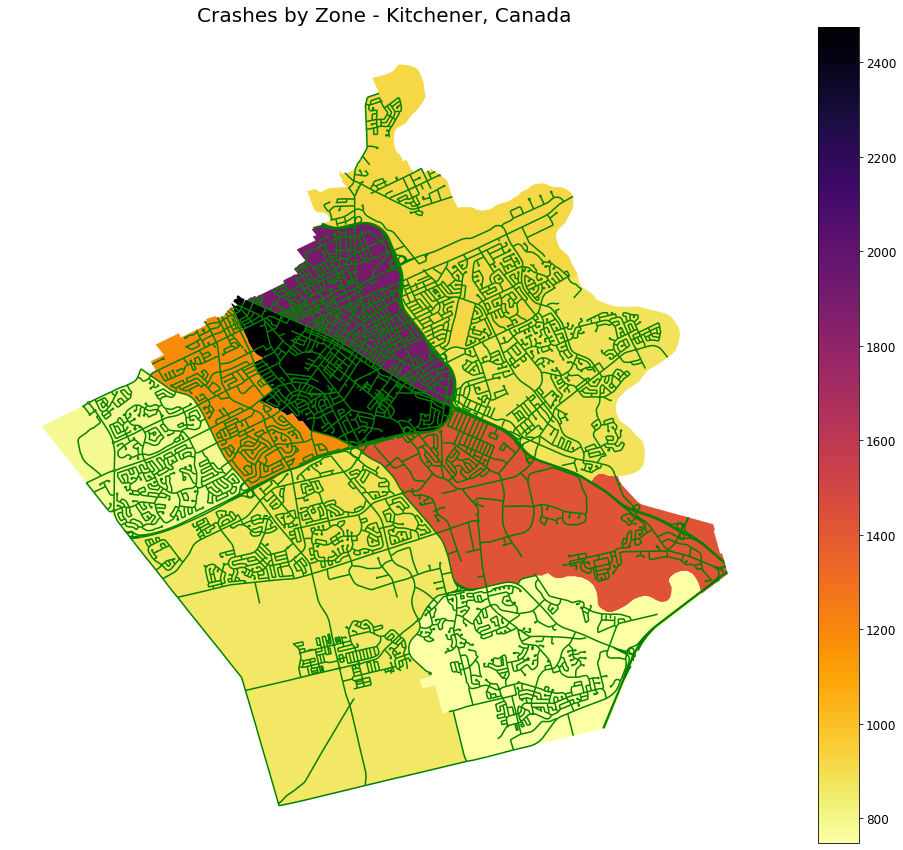
Another team plotted the accidents, the most dangerous areas of the city (see Figure 2), and the most dangerous roads. Depending on the features used, the biggest contributing factors were the light conditions, the speed limit of the street, and the width of the road.
The main opportunity for the models proposed by the teams is to help local governments and law enforcement identify dangerous zones to improve them or have better patrolling in those areas.

